The target of this week is to 1) introduce the idea of bootstrapping; 2) measure the facilities of label models that have discussed in the blog of Week 4 during bootstrapping.
Overview of Bootstrapping
The supervised machine learning needs a lot of labeled data, while it is difficult to achieve if we start from some snippet in reality. Since we have recognized some high-precision seed pairs of causality relations. It is enough to bootstrap a classifier
In the task of semi-supervised relation extraction, bootstrapping proceeds by considering the entities in the seed pairs, tagging those sentences that contain both entities and generalizing the context around the entities to learn new patterns 1.
However, before we go deep into the discussed step, it is really interesting to check whether our Label Model (or the independent labeling functions) could continue to tag the positive examples in the increasing iterations during bootstrapping. It will be the focus of this week’s blog.
Bootstrapping - version 1
Data passing procedures
At first, it is necessary to acknowledge the data processing procedures of bootstrapping. Please check the following figure:
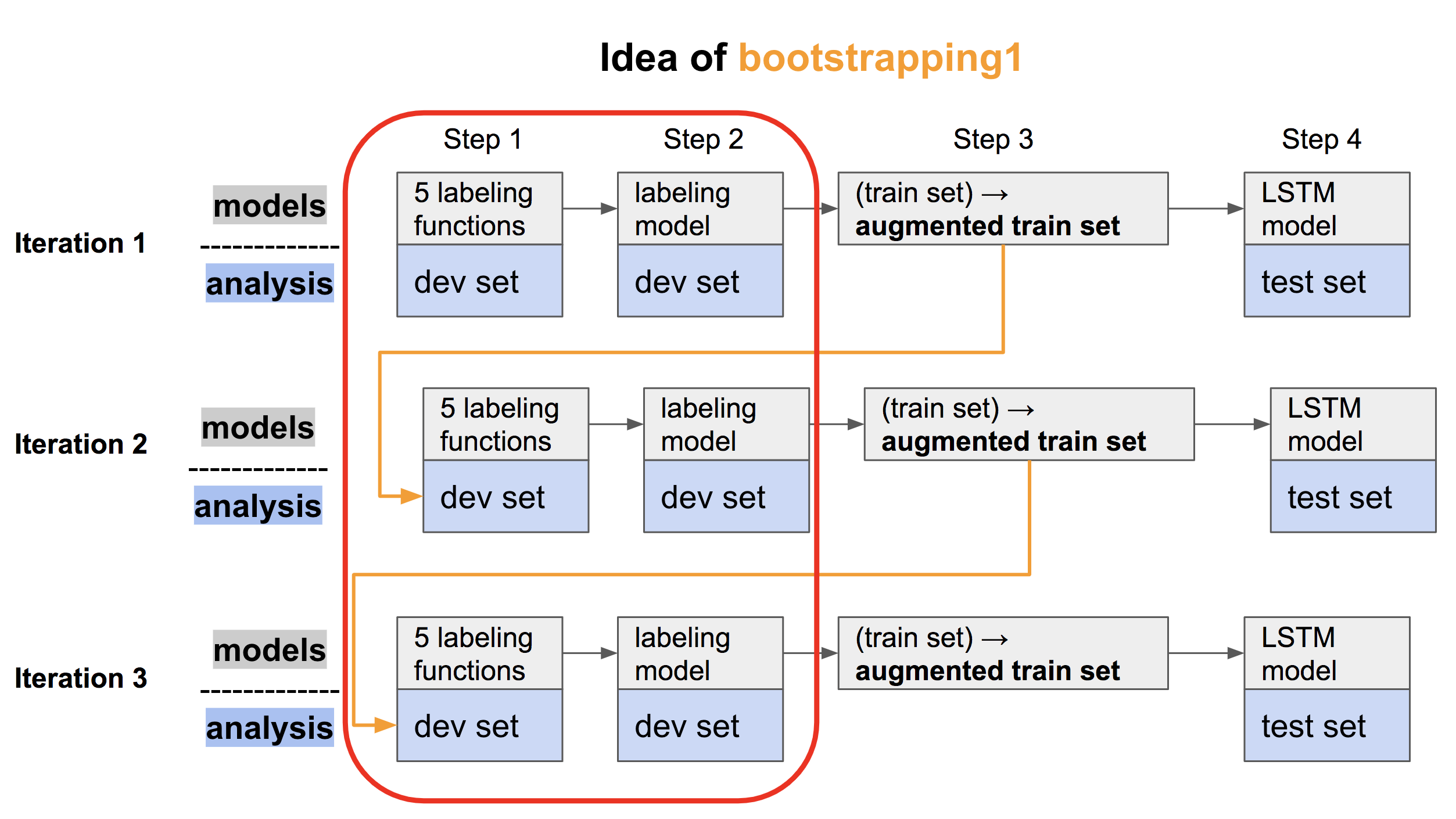 Fig1
Fig1
In Fig 1, each row represents one iteration of the trained models(in gray boxes) and the corresponding datasets (in blue boxes) on which the model is evaluated. In Step 1, we would evaluate the 5 different labeling functions on dev set; then in Step 2, the labeling model which is composed by those labeling functions will provide the integrated prediction on dev setfor those positive examples, and Step 3 and Step 4 is following. As shown in the red box, we will only focus on the first two steps in this blog.
Labeling Functions
As we discussed, we expect to include the predicating positive examples in next round. To do so, first we need to set a learning rate or confidence score, also a threshold, to examine which examples are positive (exceeding learning rate) and negative (lower than learning rate). In our experiment, we set the learning rate as 0.9, 0.8 and 0.7 as comparison.
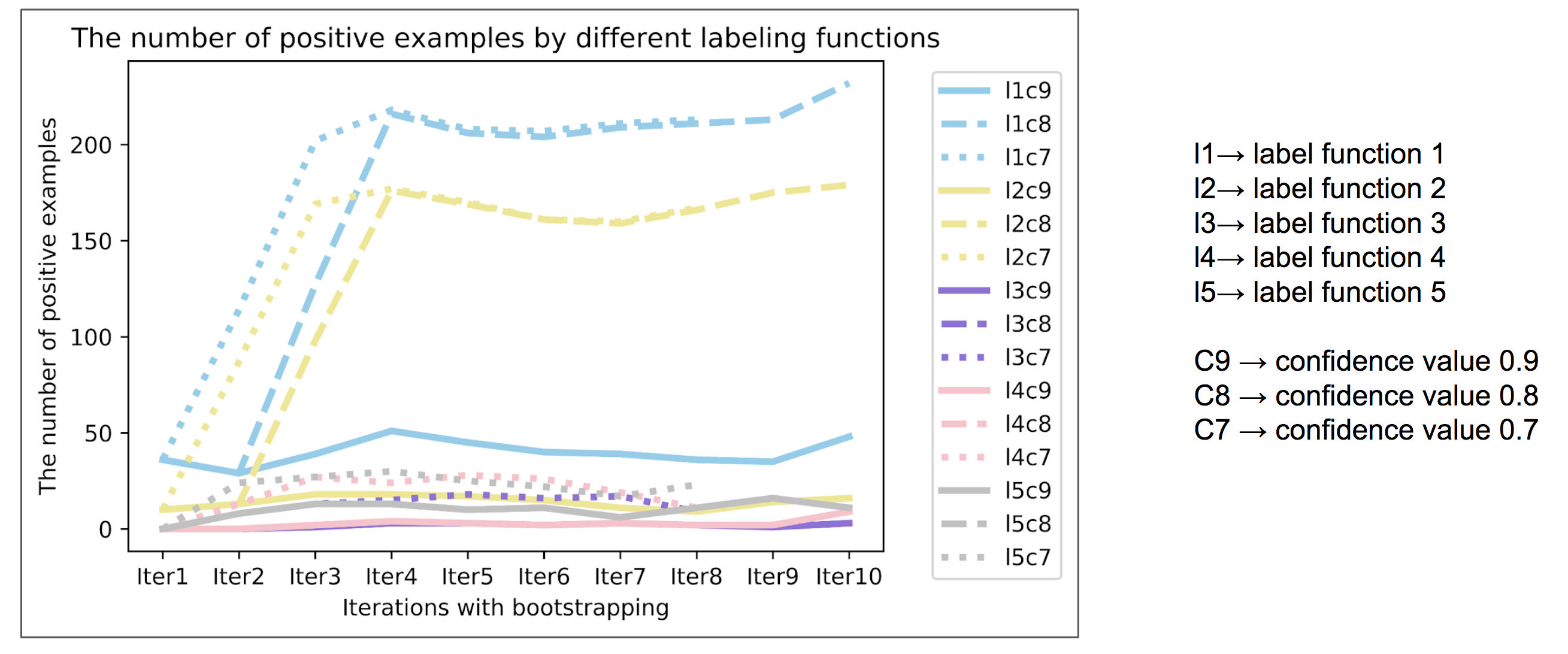 Fig2
Fig2
In Fig2, we provide the number of positives examples by different labeling functions. The iteration 1 indicates the source data without bootstrapping, we notice the great increases in iteration3 for labeling function 1 and 2 with confidence score 0.8 and 0.7. However, for other cases, it shows little improvements along with the iterations. We could conclude that the labeling function 1 and 2 is more effective in tagging positive examples than other functions during bootstrapping.
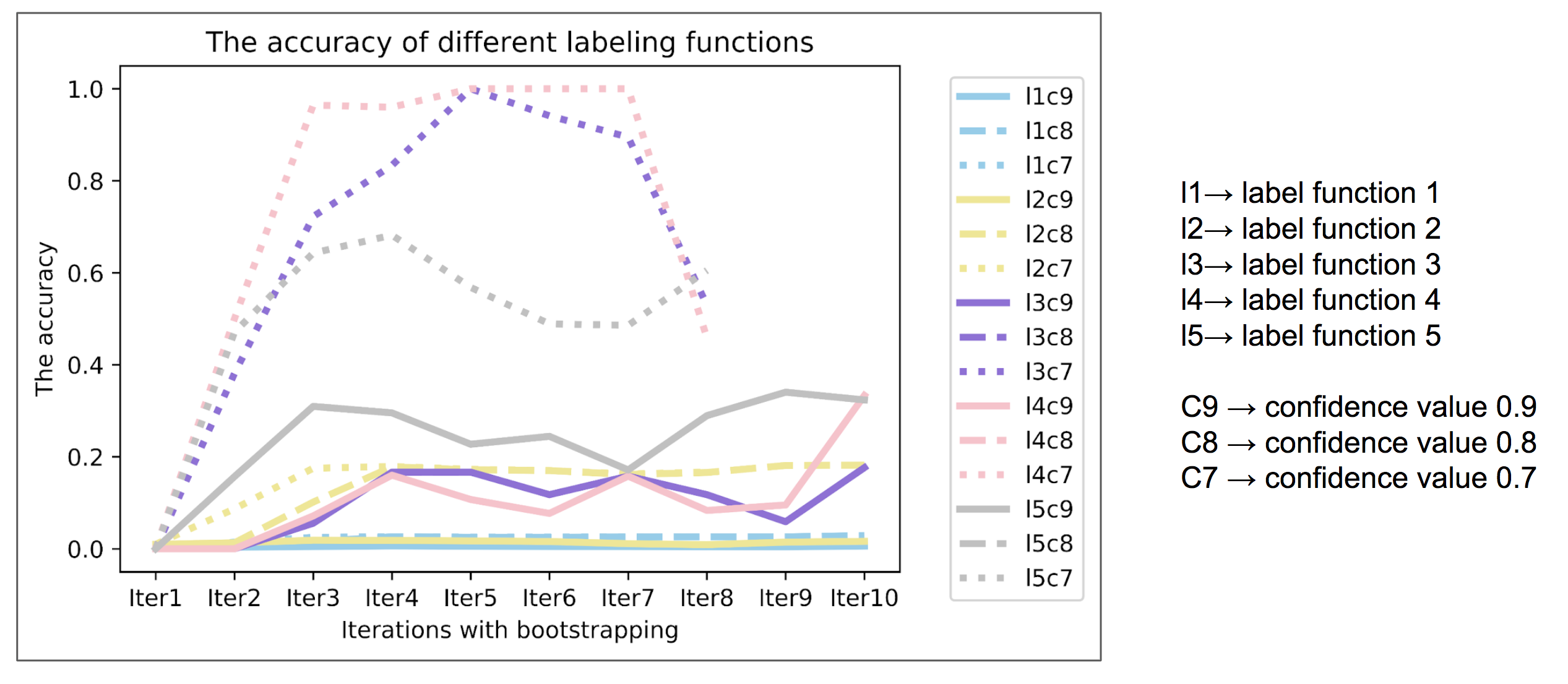 Fig3
Fig3
Also from Fig3, we could conclude that the lower the confidence score the higher the accuracy value.
Label Model
As we talked, Label Model integrates the performance of 5 labeling functions. In the following figure, we present the evaluation results for the Label Model:
accuracy = TP+TN / (TP+FN+FP+TN)
precision = TP/ (TP+FP)
recall= TP/ (TP+FN)
F1 = 2 * precision * recall / (recall + precision)
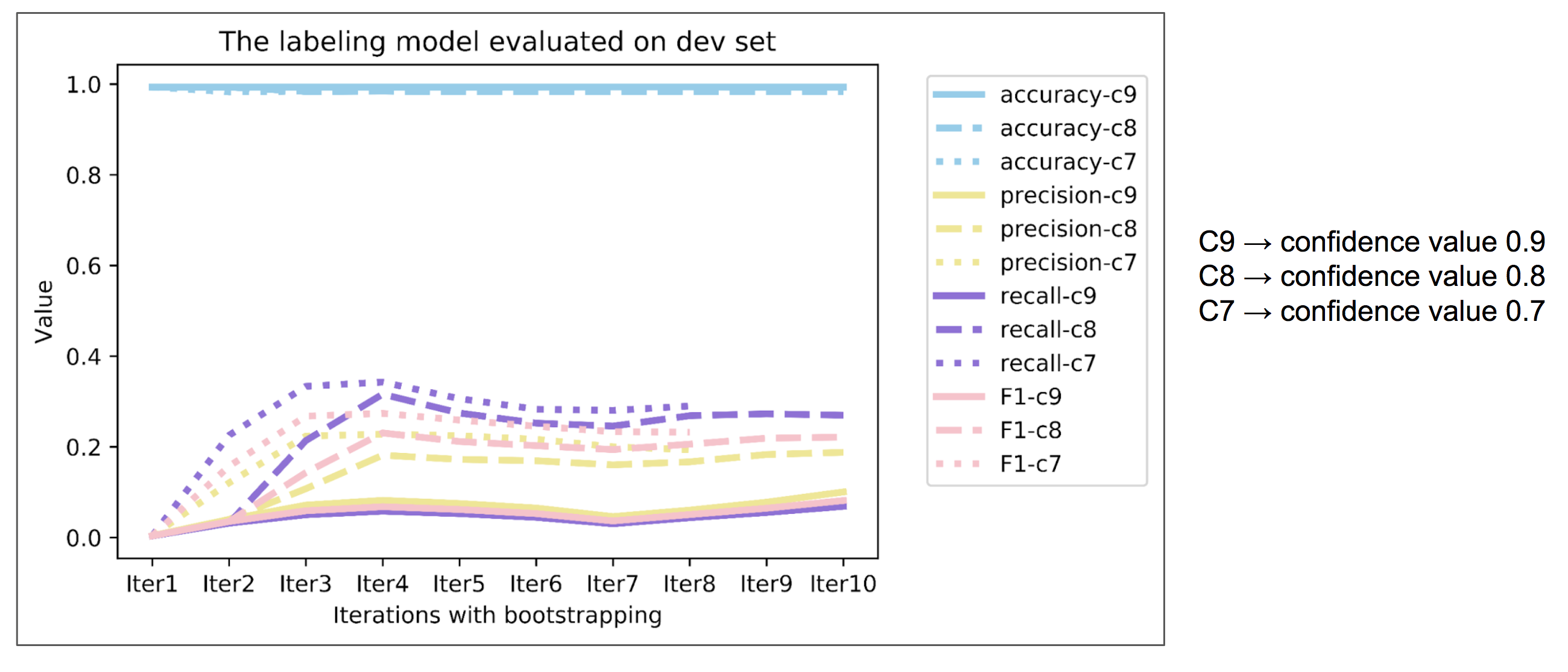 Fig4
Fig4
We notice that except for the accuracy value, other metrics, e.g. precision, recall and F1, have rather low value. This phenomenon indicates that the labeling model does not have a high performance in recognizing the positive examples.
In next week, we will continue to explore the performance of classifier based on this bootstrapping approach.