The target of this week is to 1) apply bootstrapping on classifiers in the formal ways; 2) evaluate the performance of different well-trained classifiers, e.g. LSTM and Logistic Regression.
Bootstrapping - version 2
Previously, we used bootstrapping on different sections of the same dataset. In this blog, we try to train the classification model on one dataset, i.e. SemEval Dataset, and assist with bootstrapping from another dataset, i.e. WikiPages Dataset.
Seed preparation
As we discussed, we tried to extract the causality pairs from SemEval dataset (see the details in this blog ). In order to use the complete causality information where the causal pairs occurred, we plan to extract the pairs-occurred sentences and complete with some structured information into dataframe format as the training preparation.
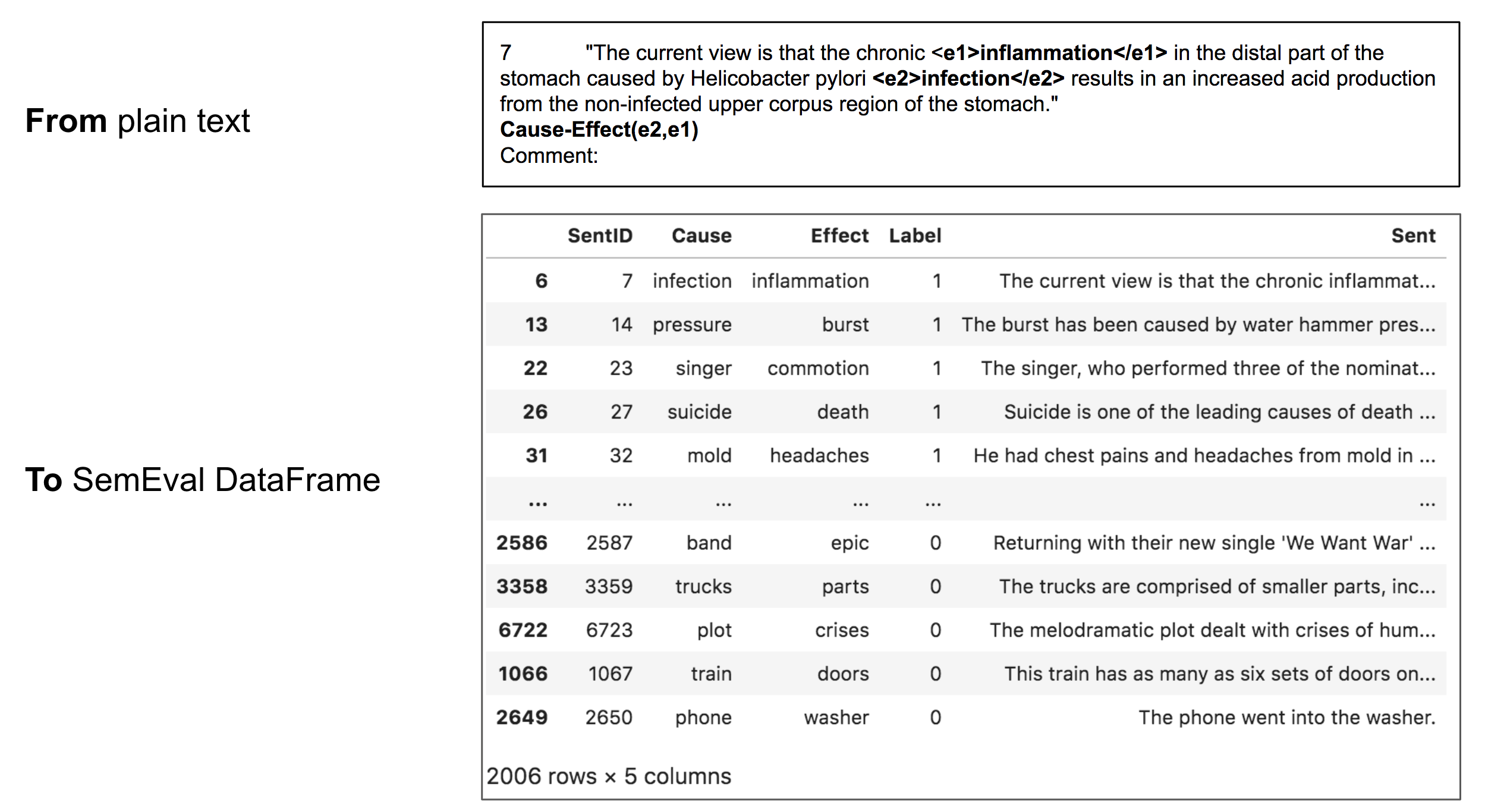 Fig1
Fig1
As shown in Fig1, we process the plain text into SemEval DataFrame. In the plain text, the causal pairs are tagged within sentence and we extracted this information into dataframe and provide the label to this sentence. If the value of label is equal to 1, it means that the causality sentence is correct, otherwise, it is not causality sentences.
Wiki data preparation
Once we acquired the causal seed pairs, it is feasible to tag this pairs in other datasets, i.e. WikiPages datasets. Meanwhile, in the side of dataset, it is required to recognize a pair of entities from sentences to prepare for model training.
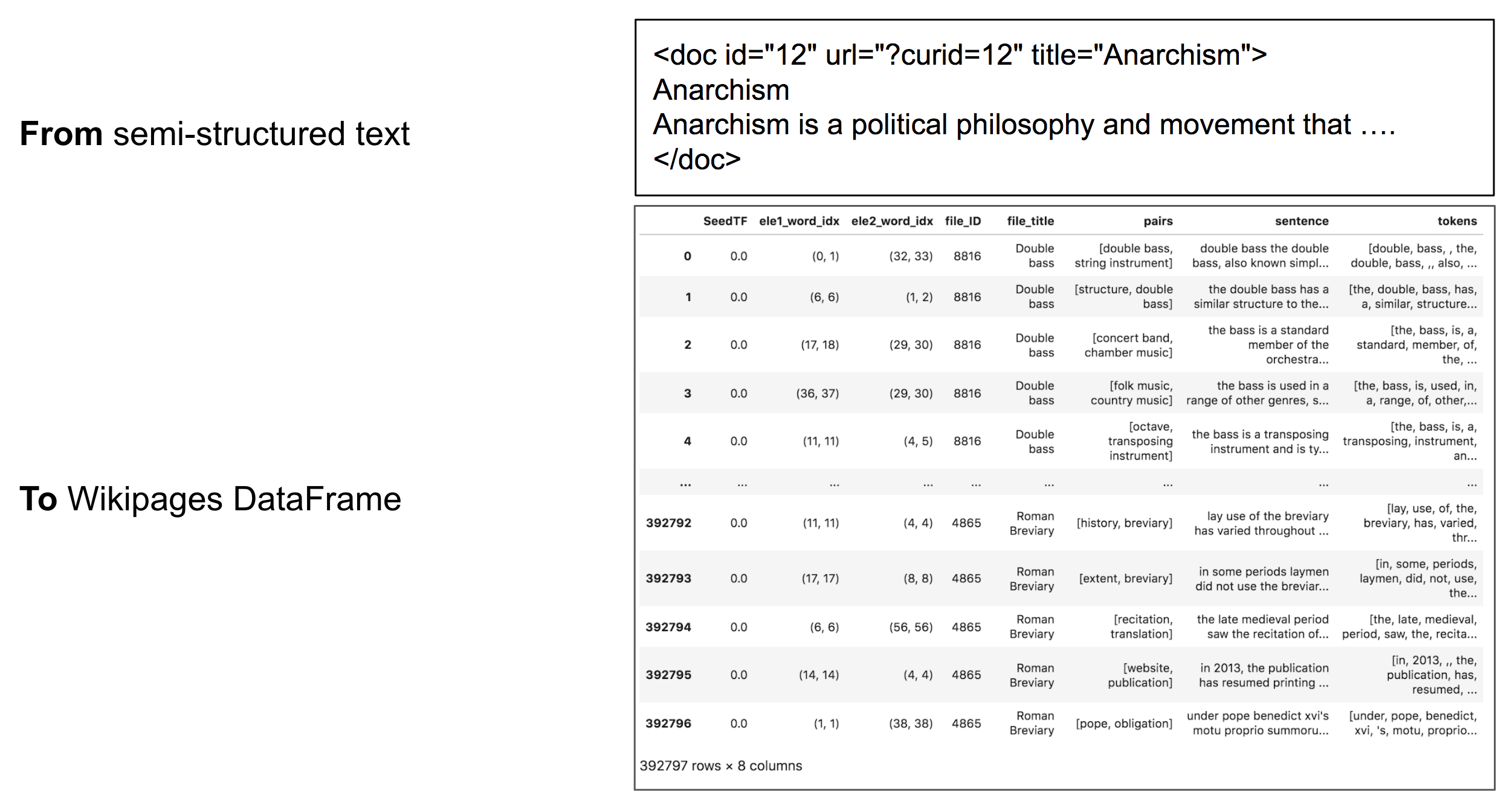 Fig2
Fig2
Fig2 presents the semi-structured text of a document and we resolve them into the structured dataframe, where the column ‘SeedTF’ indicates whether the seed pairs occur in this sentence, column ‘ele1_word_inx’ and ‘ele2_word_inx’ shows the index of this pairs in a sentence.
Classification models
After we have well prepared the datasets with semi-structured format, we need to transform the text information into the numerical feature vectors. To achieve this, we apply the embedding techniques, especially for sentence embedding (i.e. Doc2Vec models from gensim ), over the semi-structured datasets.
For simple classifier, the sentence embedding is enough for information transformation, however, for the neural classifier, LSTM, we manage to divide one sentence into 3 different sentences embeddings, as presented in Fig3.
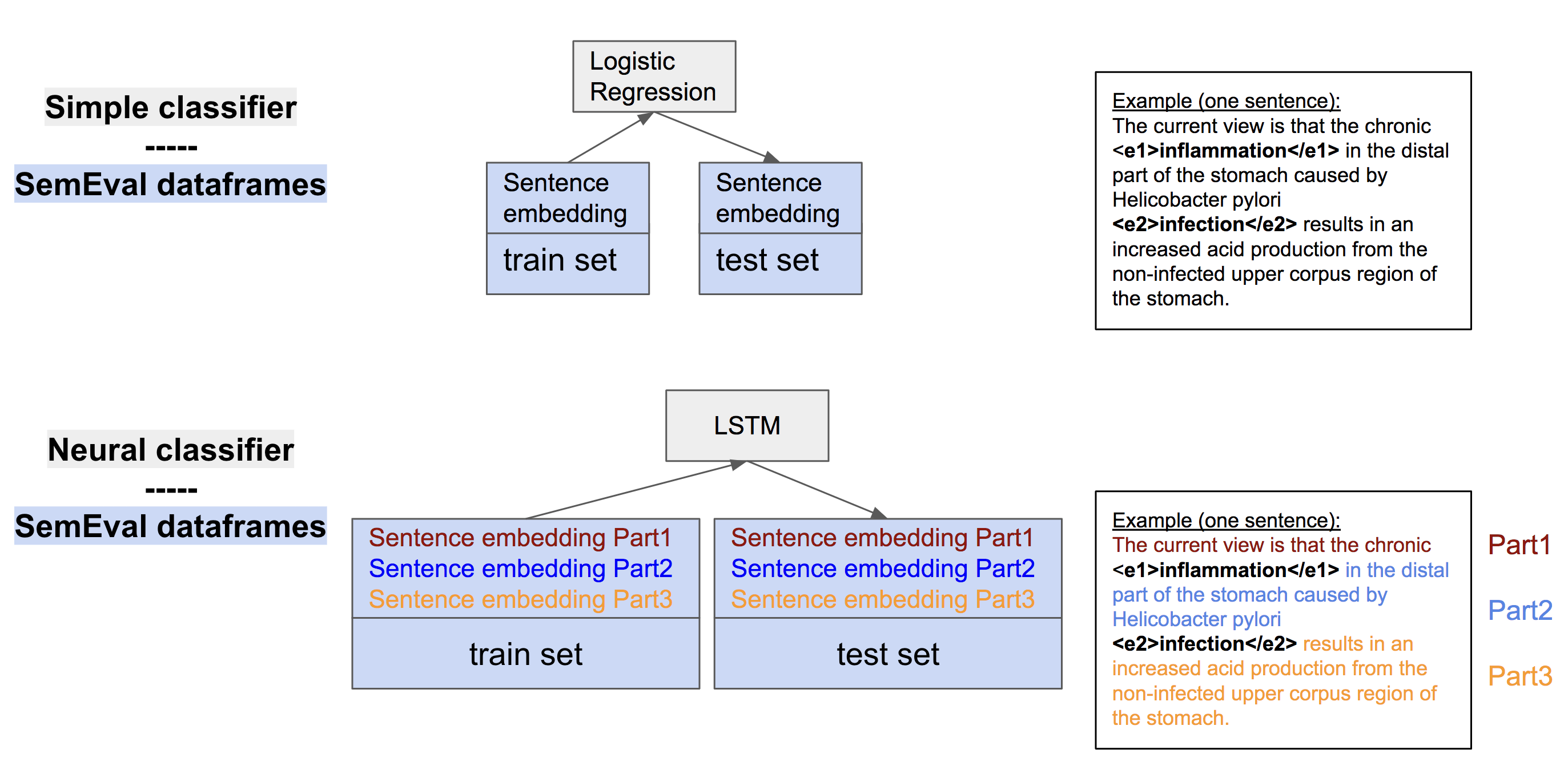 Fig3
Fig3
Classification models with bootstrapping
In the bootstrapping procedure, those classifiers are trained in different round with adding up some positive examples from another dataset. For example, we present the first 2 rounds of bootstrapping while indicating the source of datasets in orange color.
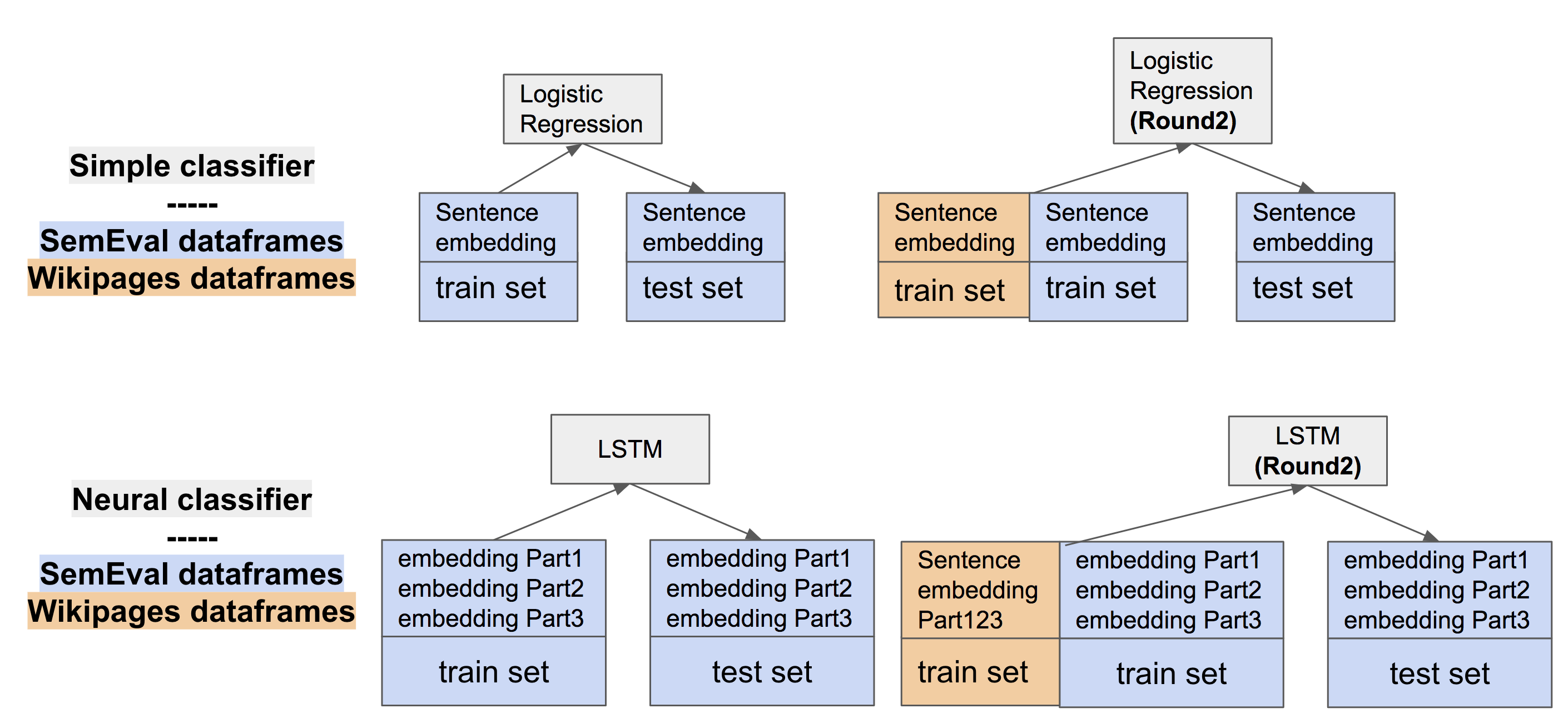 Fig4
Fig4
Performance of classifiers
Now, it is time to evaluate the classifiers during bootstrapping:
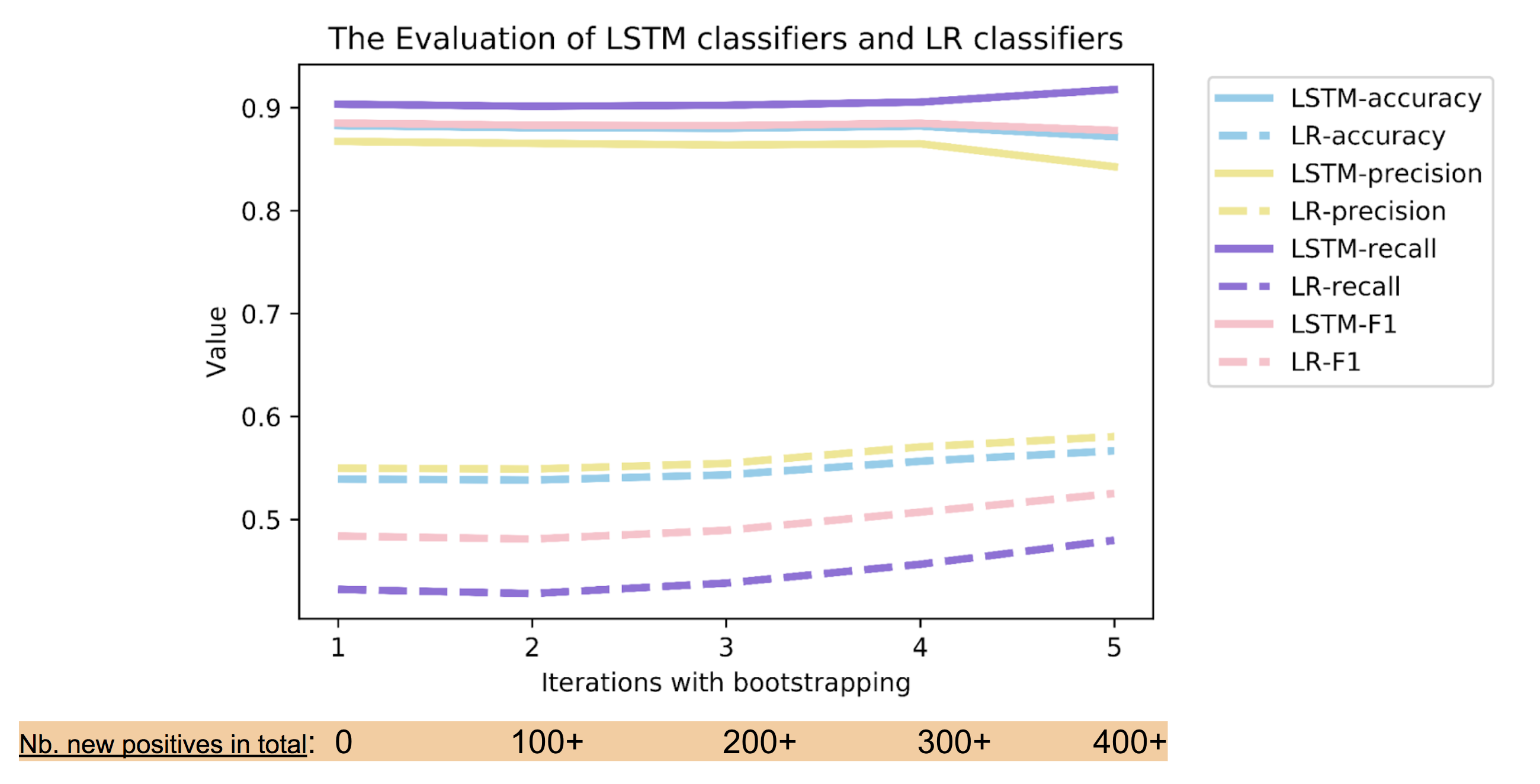 Fig5
Fig5
We notice that the whole performance of LSTM is rather better than other classifiers, also better than its previous performance. It is due to the advanced parameter tuning and the final successful convergence. After Iteration4, the performance of LSTM slightly dropped. However, for Logistic Regression, it continues to make small gains along with increasing of iterations. As we see from the bottom orange lines, the increasing iterations conforms to the growing new positive examples during training.
Briefly, the neural classifier, i.e. LSTM, performs well for relation recognition, however, it is not as sensitive as other classifiers regarding to bootstrapping’s benefits.
The END