The target of this week is to 1) continue to apply the classifiers in blog of Week 6; 2) measure the facilities of different classifiers.
Bootstrapping - version 1
Data passing procedures (continued)
At first, it is necessary to acknowledge the data processing procedures of bootstrapping. Please check the following figure:
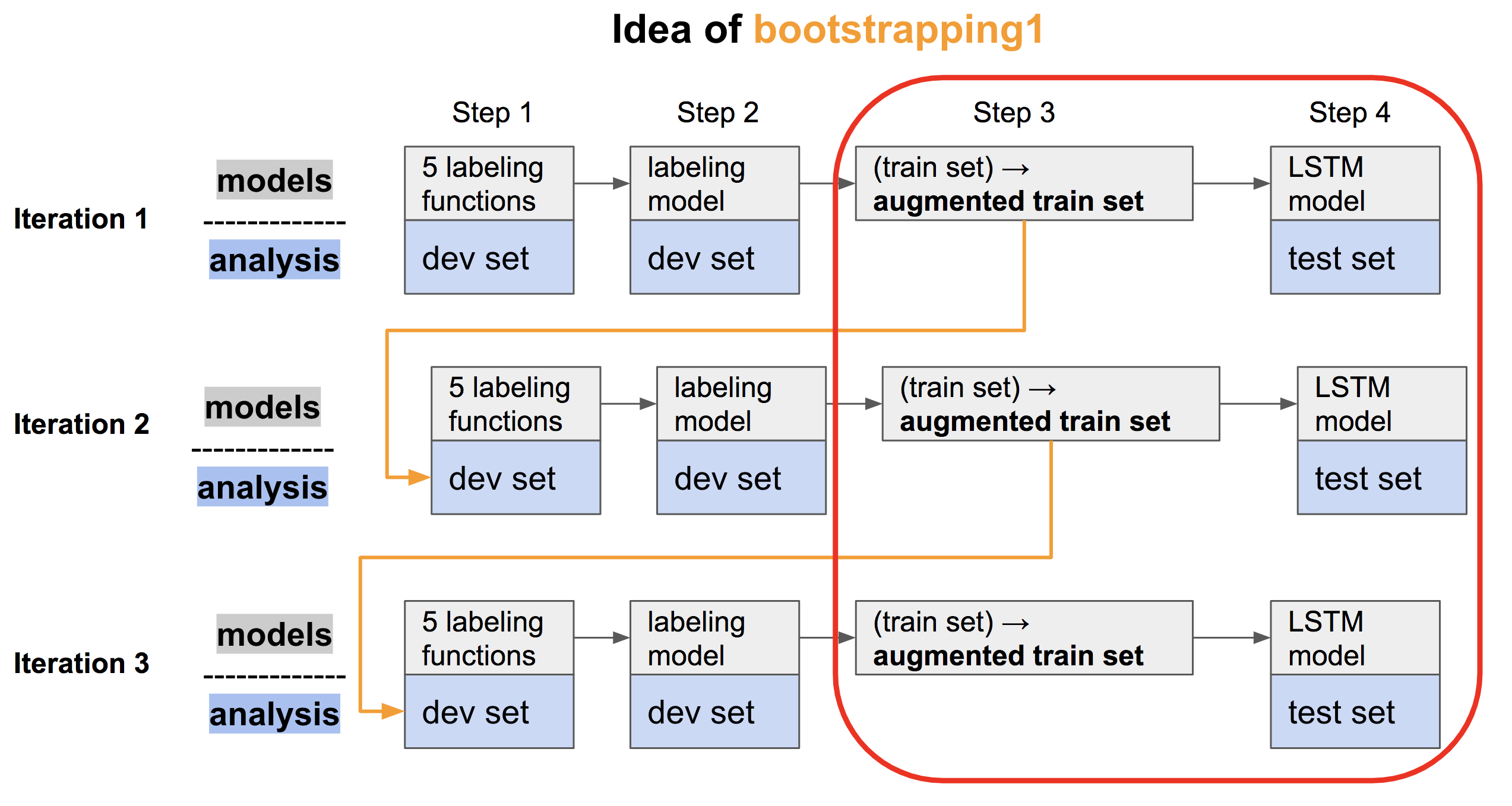 Fig1
Fig1
In Fig 1, each row represents one iteration of the trained models(in gray boxes) and the corresponding datasets (in blue boxes) on which the model is evaluated. In Step 1 and Step 2, the labeling model provided the integrated prediction for those positive examples. In Step 3, the predicated positives will form the augmented train set and it will be used to learn a classifier in Step 4, e.g. LSTM (talked in Week5’s blog). As shown in the red box, we will only focus on the last two steps in this blog.
Augmented train set
If we want to augment dataset with the high predicated positive examples, it is interesting to learn about the increasing amount of positive examples in different iterations.
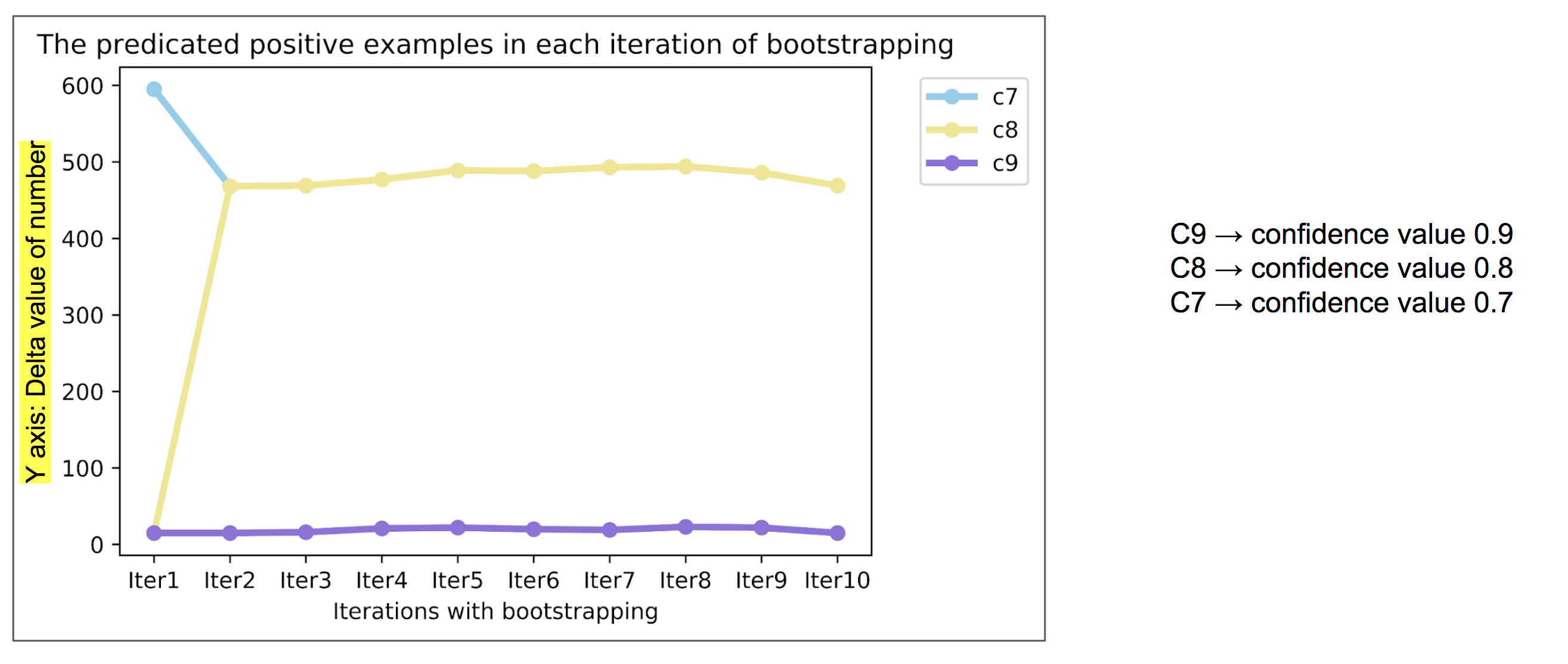 Fig2
Fig2
In Fig2, we provide the delta number of positives examples along with the increasing iterations in X-axis. The iteration 1 indicates the source data without bootstrapping, we notice the great increases in iteration 2 for confidence score 0.7 and 0.8. However, for the case confidence value 0.9, it shows no improvements along with the iterations. We could conclude that the confidence value 0.7 and confidence value 0.8 are more effective in tagging positive examples to augment the dataset.
Classifiers
We trained the LSTM on the augmented train set and evaluated with 4 metrics:
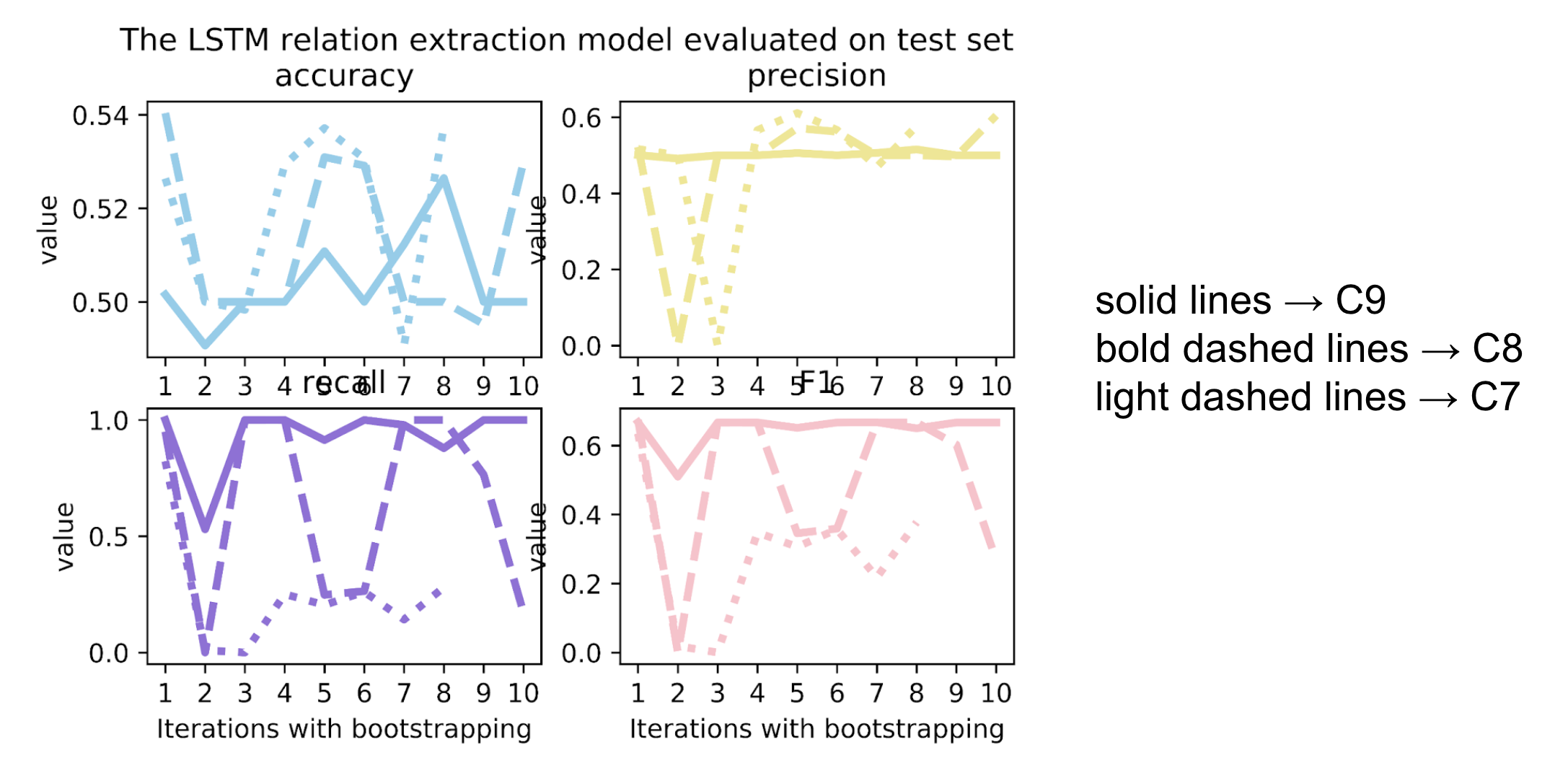 Fig3
Fig3
Unfortunately, most of the accuracy and precision values are around or below 0.5, which is rather the worst performance as a classifier.
Except for it, we also tried to train others classifiers, e.g. Logistic Regression and SVM, as comparison.
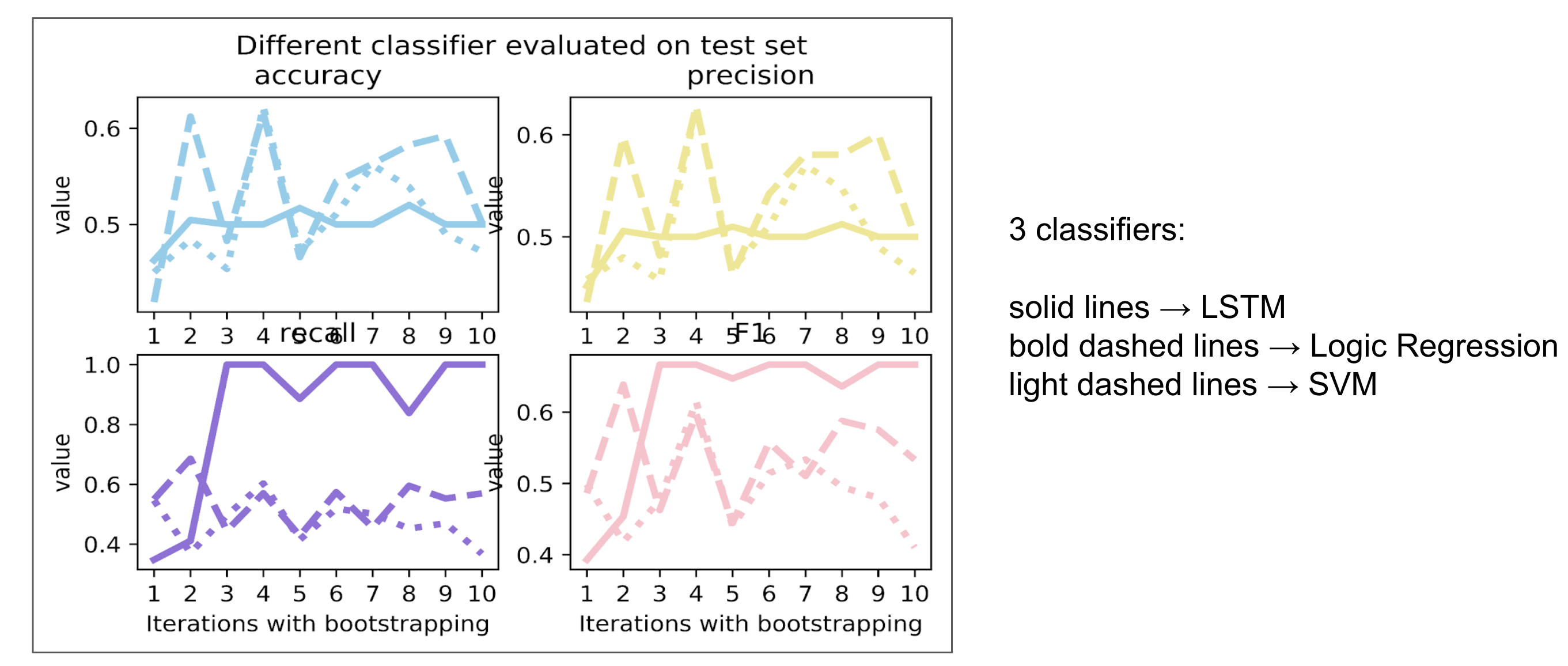 Fig4
Fig4
From Fig4, we observed that logistic Regression and SVM have fluctuate performance but even better than LSTM.
Briefly, we assume that the LSTM is not well converged, which needs more exploration of parameter tuning. Meanwhile, it is also interesting to focus on logistic Regression for more details.